Description:
Several releases ago I tested simple cluster of GlusterFS. My purpose was to replace DRBD master-slave schema (lvm -> drbd -> nfs), which not supported by Ovirt as native storage. In that time I was not able to achieve expected behaviour in self-healing and replication, but today I will try again.
For this, I created some test environments:
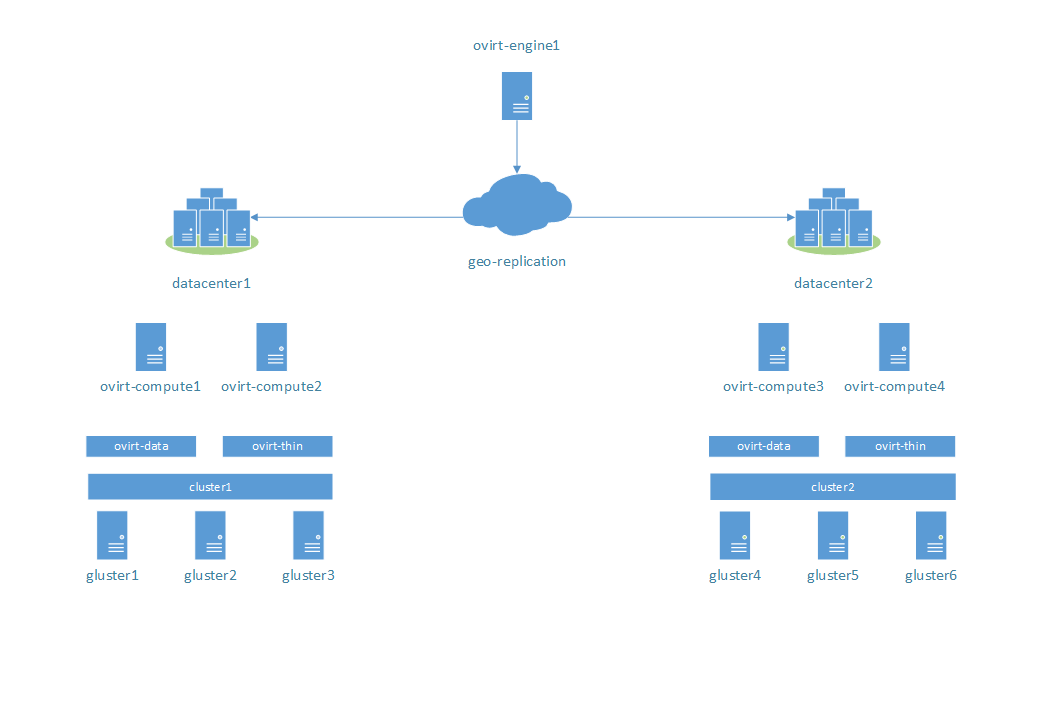
Ovirt: 2 datacenters, 2 clusters, 2 compute nodes in each.
GlusterFS: 2 clusters, 3 nodes in each, 2 bricks on each node. Volumes: ovirt-data placed on standard partition, ovirt-thin placed on thin provisioned LVM volume. 3-way replication for each volume. BitRot enabled for each volumes. Geo-replication between cluster1 and cluster2.
Main diagram:
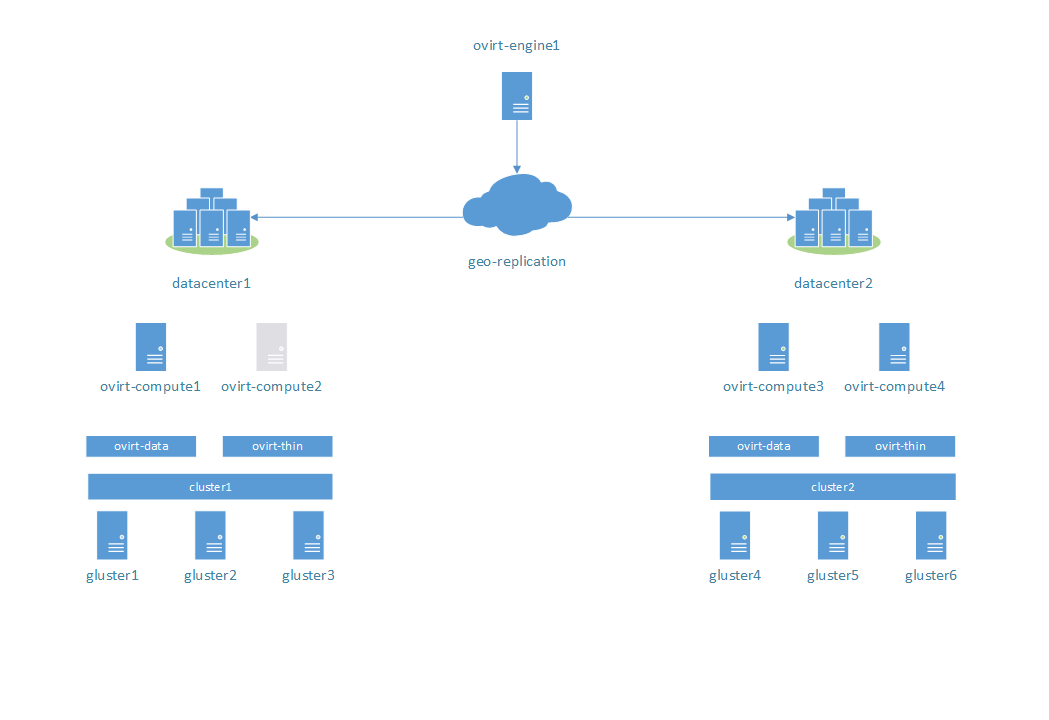
Stage 1:
The virtual machine running on ovirt-compute2, which suddenly switched off. Expected behaviour: virtual machine should start working on ovirt-compute1.
Result: success
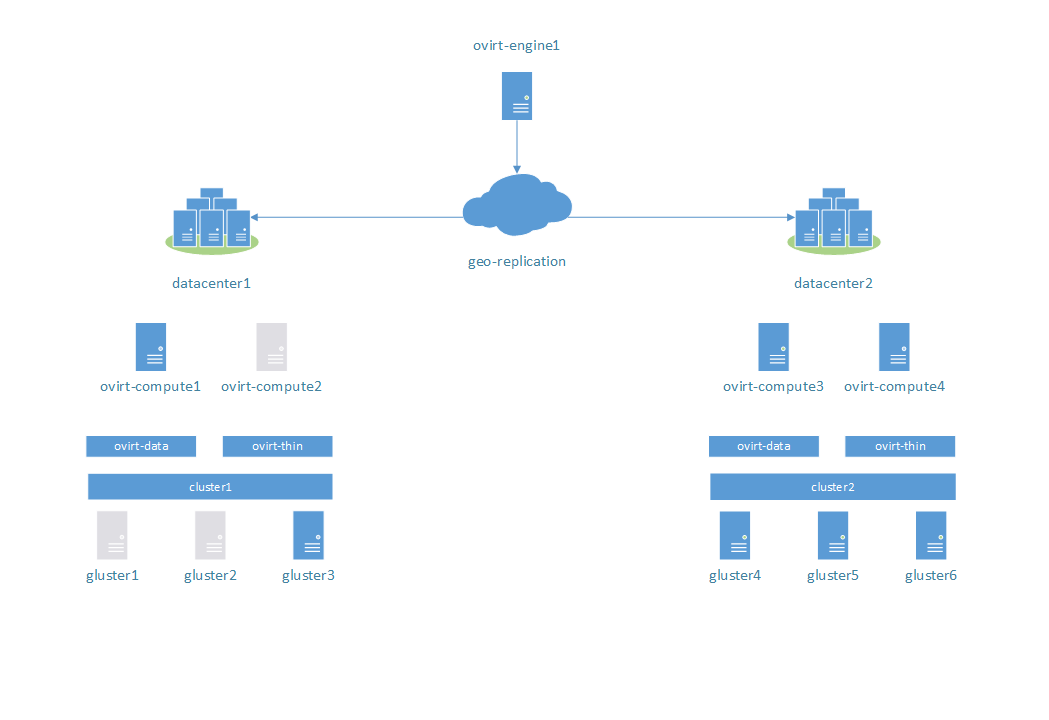
Stage 2:
Two members of cluster1 suddenly switched off. Expected behaviour: virtual machine should continue working.
Result: success.
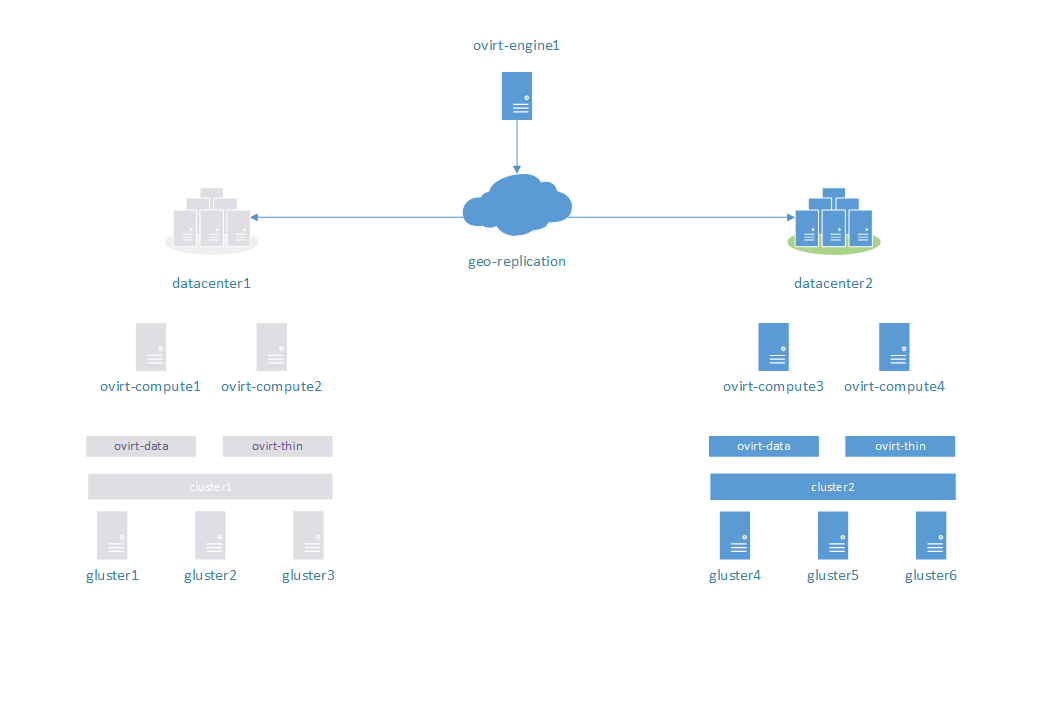
Stage 3:
datacenter1 completely down. Expected behaviour: destroy unavailable ovirt-data storage in datacenter1, import replicated ovirt-data storage to datacenter2, import virtual machines and start working.
Result: success.
Stage 4:
datacenter1 returned to work. Expected behaviour: after crash on Stage 3 we set replicated volume act as master, therefore changes that were made to the virtual machine will not be lost.
Result: success
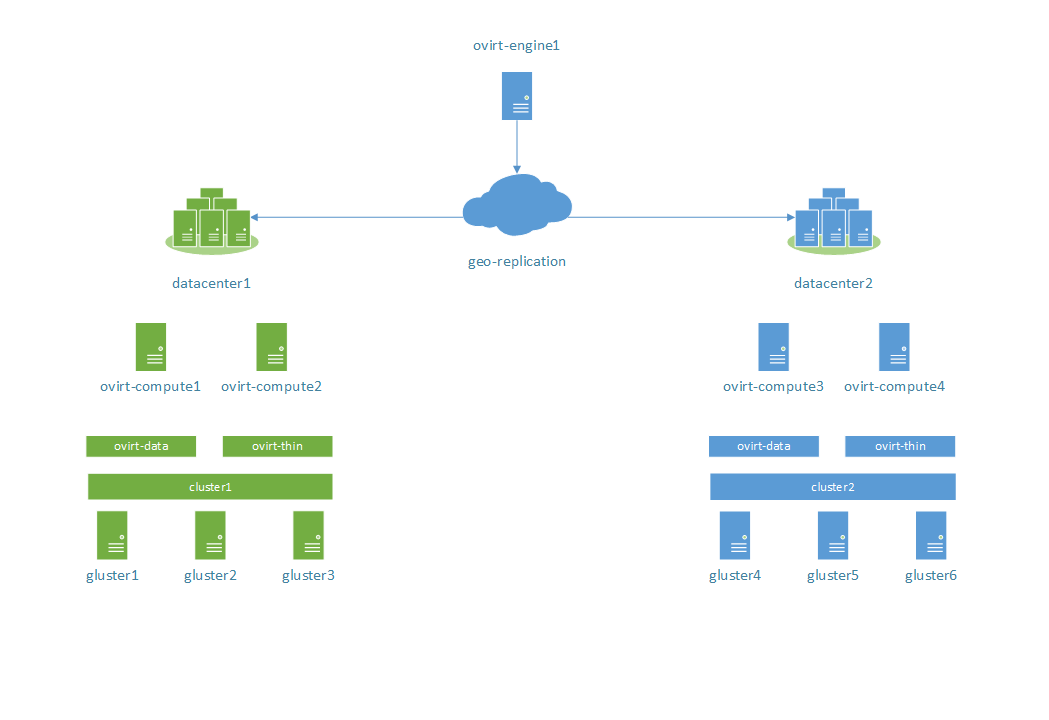
Stage 5:
Return original master-slave roles. Expected behaviour: replicate original slave storage to original master storage and set cluster1 as master.
Result: success
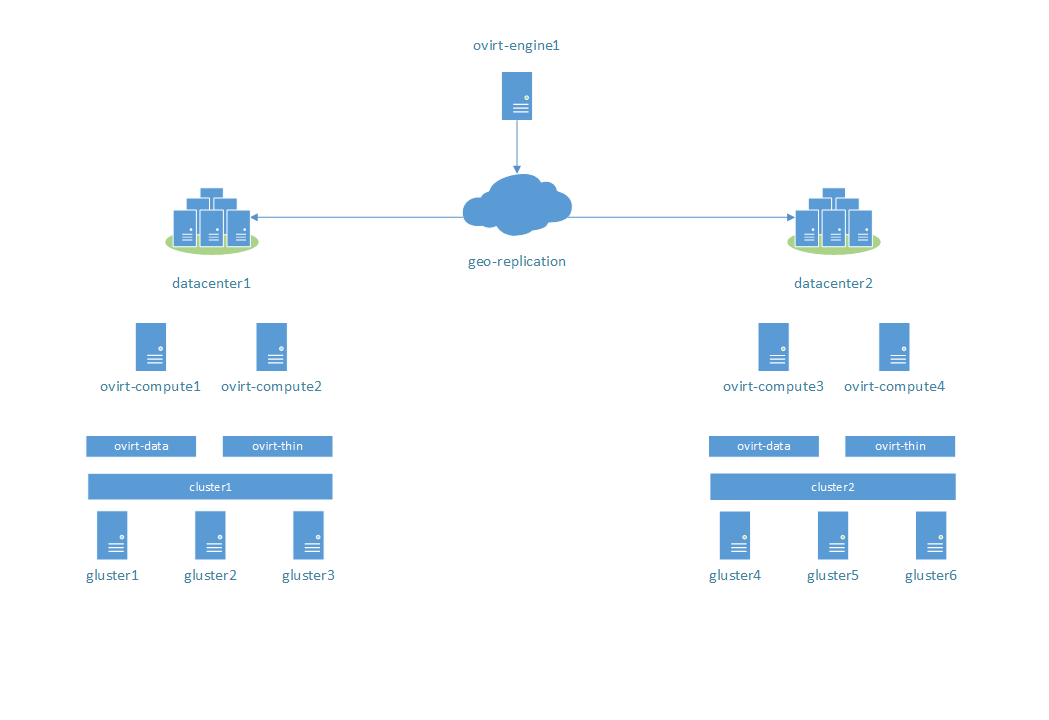
Stage 6:
On gluster3 was corrupted HDD disk of virtual machine. Was corrupted through method, that doesn't use GlusterFS translators (emulate HDD problems). Virtual machine is in running state. Expected behaviour: ?
Result: After discovery of checksum mismatch of virtual disk all operations I/O for this disk will be rejected. But virtual machine will be work with valid data from other replicas. If all valid replicas go down, except of invalid, that virtual machine will be paused with error code "VM has been paused due to a storage I/O error".
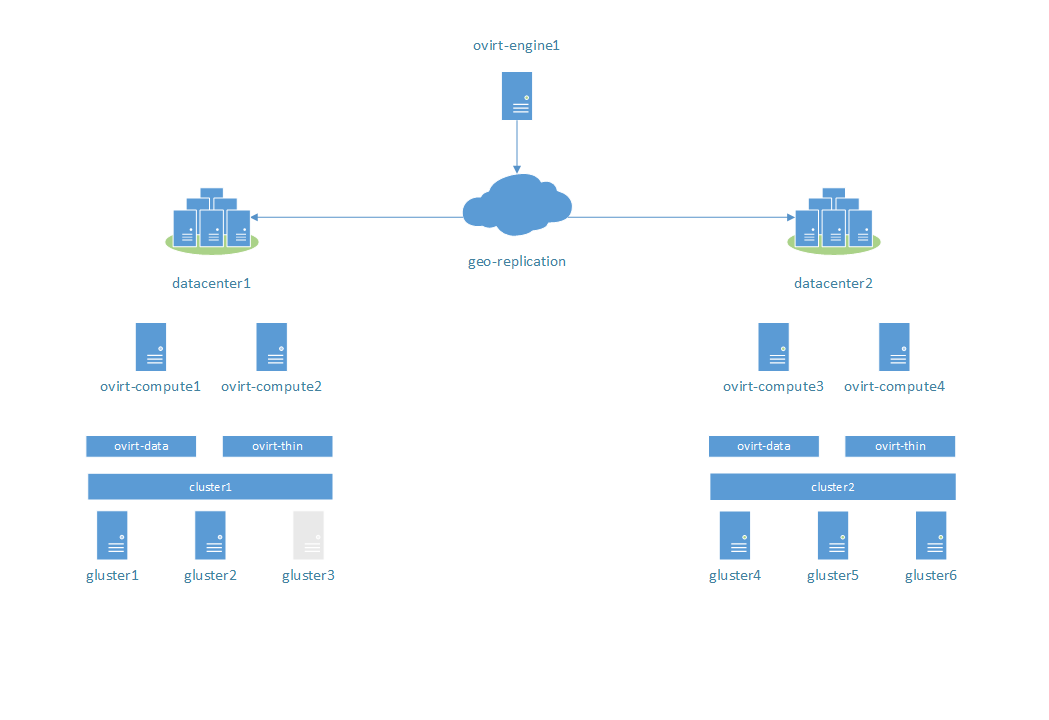
Stage 7:
Create several snapshots of ovirt-thin volume and create new ovirt-thin-clone volume from them. Expected behaviour: ?
Result: success
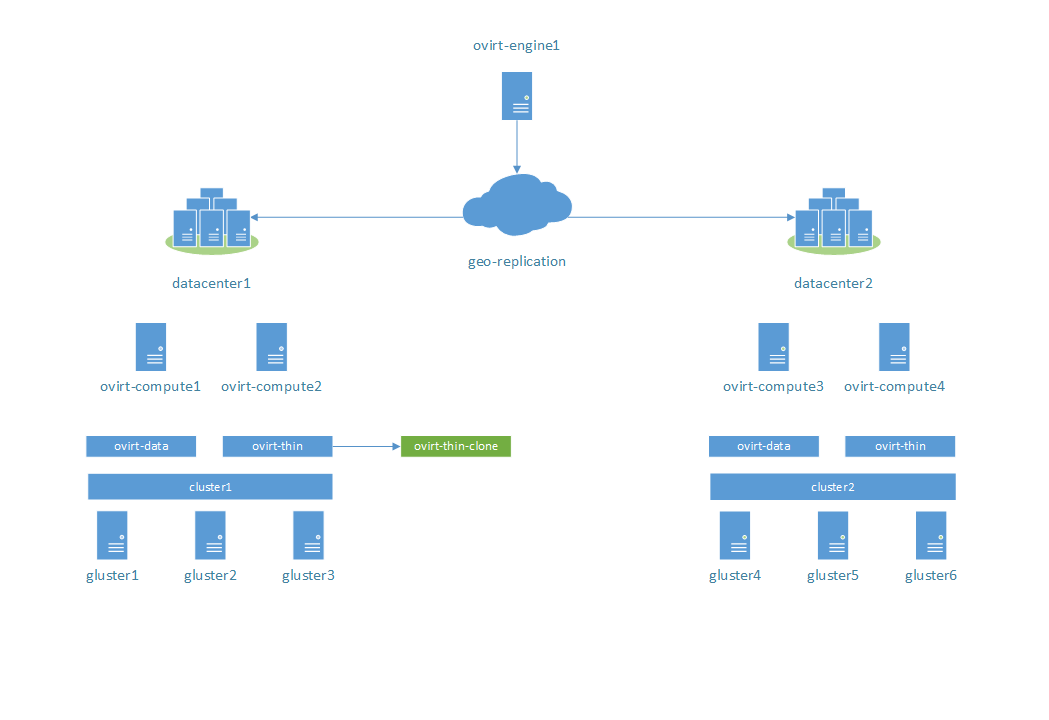
To be continued ...